Tutoriel – Utiliser ReaderBench pour analyser automatiquement des discussions#
Informations
Auteurs : Philippe Dessus, Inspé & LaRAC, Univ. Grenoble Alpes, & Nadine Mandran, LIG-CNRS, Univ. Grenoble Alpes.
Date de mise à jour : Novembre 2022. Document créé en Octobre 2020.
Résumé : Ce document explique la procédure à suivre pour analyser automatiquement des discussions pour apprendre ou construire des connaissances avec ReaderBench, un système d’analyse sémantique textuelle.
Documents associés : CONPA : Un jeu de création et réflexion sur l’usage du numérique.
- Fichiers associés :
Voir aussi : Document Outils d’analyse textométrique pour l’enseignement.
Note : Ce document complète et reprend les informations d’un chapitre d’ouvrage : Dessus, P., Dascalu, M., Mandran, N., Gutu-Robu, G., Dormoy-Fournier, C., & Ruseti, S. (à paraître). L’analyse sémantique automatique pour étudier les discussions visant la construction collaborative de connaissances. In B. Albero & J. Thievenaz (Eds.), Traité de méthodologie de la recherche en sciences de l’éducation et de la formation. Dijon : Raison & passions.
Introduction#
Les discussions (ou débats) sont de bons moyens pour permettre à des apprenants de débattre d’un sujet, et d’approfondir collaborativement leurs connaissances, que ces débats se réalisent en présence ou à distance, via des plates-formes et des forums ou chats. Pour autant, il reste difficile pour l’enseignant animant ces débats, ou le chercheur qui veut les étudier, d’en avoir une vision immédiate : leur analyse est coûteuse en temps. Il existe des logiciels d’analyse automatique qui autorisent une première représentation des contributions de chaque participant, par exemple. Dans ce tutoriel nous allons montrer comment utiliser ReaderBench à cette fin.
ReaderBench est un outil d’analyse automatique de productions écrites liées à l’apprentissage. Il est multilingue (anglais, français, italien, espagnol, roumain, néerlandais) et utilise des méthodes de traitement automatique de la langue éprouvées pour analyser la cohésion entre composants du texte (phrases, tours de parole, documents, etc.). Il a été conçu par la mise en œuvre de deux modèles différents et complémentaires. Le modèle de la cohésion est opérationnalisé comme la mesure de similarité moyenne entre entités du texte (mots, phrases, tours de parole, conversation complète). Un graphe de cohésion entre tours de paroles est construit, composé d’un nœud central (la discussion complète) décomposé en tours de parole, puis en phrases, les liens entre ces nœuds symbolisent des relations de cohésion fortes. Ce mécanisme permet d’évaluer la contribution de chaque participant en rapport avec la discussion complète, mais aussi avec les contributions des autres participants. Des liens sont créés entre tours de parole : leur poids est d’autant plus grand que ces tours de parole sont sémantiquement proches. Ces liens sont bi-directionnels pour chaque nœud, selon qu’ils sont reliés aux tours de parole avant un tour donné, ou après. Le reste de ce document détaille la procédure pour analyser une discussion collaborative.
Nous utilisons ici le module CSCL (computer-supported collaborative learning) accessible ici : https://readerbench.com/services/cscl
Procédure#
Description du corpus utilisé#
À titre d’exemple, nous allons analyser les données produites lors d’une séance de test d’un jeu sérieux pour l’élaboration de questions de recherche en technologie de l’éducation, CONPA (Dessus & Jolivet, 2016), voir CONPA : Un jeu de création et réflexion sur l’usage du numérique pour les règles du jeu. Le jeu CONPA, pour Comportements, Outils, Notions, Pensée, Actions, les différents thèmes des cartes du jeu) est un jeu de table librement inspiré du jeu MotivéSens (Broc et al., 2017), et permet de stimuler la conception de situations de recherche et développement (R&D) d’usages innovants du numérique en situations scolaires. L’activité des joueurs est de réaliser des liens (intégration) entre un problème de recherche qu’ils spécifient initialement, avec chacune des cartes qu’ils tirent tour à tour, montrant un mot-clé (voir les mots-clés des Figures 3, 4 et 5). Les joueurs raffinent collaborativement et en parallèle leur problème sur une carte de concepts personnelle, son caractère aléatoire incitant à « sortir du cadre » et imaginer des pistes de travail originales. Ce type de jeu implique les joueurs dans une démarche de co-construction de connaissances.
Pour tester ce jeu sérieux, nous avons mis en œuvre un focus group (voir Tutoriel - Mener un focus group). Après la présentation du jeu (but, principes et règles) par l’animateur, ce dernier lançait une session de jeu d’environ 1 h 30 avec les participants. Lors de cette session, tous les échanges oraux ont été enregistrés. A l’issue de cette partie de jeu, une discussion a été conduite pour recueillir les avis de tous les participants y compris l’animateur. L’objectif de cette discussion était de faire émerger de nouvelles propositions pour améliorer CONPA. Les participants de la discussion analysée plus loin étaient cinq enseignantes également étudiantes de Master 2 mention « Métiers de l’enseignement, de l’éducation et de la formation ».
Les enregistrements audio ont été transcrits dans leur intégralité. Le corpus se présente sous la forme d’un fichier texte brut comprenant un tour de parole par paragraphe. La section suivante montre comment le transformer en un fichier XML lisible par ReaderBench.
Codage du corpus#
Chaque tour de parole doit être codé entre des balises spécifiques, indiquant à quel moment de la discussion il a été produit, et par qui. Le format général est de ce type (en exemple, le premier tour de parole de la discussion) :
<Utterance genid="1" ref="0" time="2015-01-15 14:00:00.0" >C'est Mireille qui commence
</Utterance>
</Turn>
Cela signifie que l’animateur est le locuteur de ce tour, qu’il démarre la discussion (qui a démarré le 15 janvier 2015 à 14:00), elle ne réfère explicitement à aucun autre tour (ref=“0”). Il est assez aisé de concevoir un tableau dans lequel on insère les tours de parole et les locuteurs, ainsi que, le cas échéant, un horodatage (1 tour par ligne), les autres éléments étant répliqués et éventuellement incrémentés (variables time et ref). Le fichier (lisible avec n’importe quelle suite office) montre comment organiser ce codage. Les étapes suivantes sont à réaliser.
Dans la première feuille du fichier-tableur.
coller dans la colonne B du tableur les noms des participants
coller dans la colonne M du tableur les tours de parole, comme autant de lignes ;
coller les informations d’horodatage dans les colonnes I (date) et K (heure), si elles ne sont pas disponibles, en créer de fictives, par exemple en incrémentant les informations horaires par saut de 10 s.
étendre toutes les autres colonnes en vérifiant bien que les colonnes E, l’identifiant du tour et G, le temps s’incrémentent bien ;
Dans la deuxième feuille du fichier-tableur.
étendre la ligne pour voir apparaître tous les tours de parole codés dans le format approprié ;
copier l’ensemble des lignes ;
coller les lignes dans un logiciel de traitement de textes permettant les remplacements multiples ;
rechercher/remplacer les caractères € par une tabulation et les caractères $ par un retour de paragraphe ;
sauvegarder le fichier résultant dans le format XML dans le format UTF-8.
en ajoutant au début du fichier (avant les tours de parole précédents) :
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<Dialog team="1" name="CONPA">
<Body>
et à la fin du fichier, le répertoire de tous les locuteurs de la conversation.
</Body>
<Participants>
<Person nickname="Nom_locuteur_1"/>
<Person nickname="Nom_locuteur_2"/>
<Person nickname="Nom_locuteur_n"/>
</Participants>
</Dialog>
Pour faciliter les tests, voici les deux documents à télécharger :
le document tableurà compléter avec ses propres discussions ;
Traitement dans ReaderBench#
La section “analyse de discussions collaboratives” de ReaderBench est à cette URL : https://readerbench.com/services/cscl. Voici la procédure :
Téléverser le fichier XML (onglet “Import XML“) précédemment composé par un glissé-déposé ou en cliquant sur “Choisir le fichier” ;
Sélectionner la langue ;
Cliquer sur le bouton “Process” et l’analyse débute, qui peut durer plusieurs minutes selon la longueur de la discussion.
Une fois l’analyse réalisée il est possible de la sauvegarder sous la forme d’un fichier JSON (bouton “Export JSON”, et de l’importer (onglet “Import JSON“), de manière à pouvoir “rejouer“ les visualisations dynamiques sans être connecté au serveur. Deux onglets affichent l’ensemble des visualisations ci-dessous (Contributions et participants).
Analyse des données dans ReaderBench#
Voici le détail des analyses possibles une fois le traitement achevé (pouvant prendre plusieurs minutes selon la taille du corpus) :
Tableau#
Le premier document fourni est un tableau reprenant tous les tours de parole et donnant toutes les informations qui feront ensuite l’objet de graphiques. Le tableau n’est pas directement exportable mais un copier-coller de l’ensemble permettra de le sauvegarder dans un tableur. Notons aussi qu’on peut réaliser un classement alphabétique des données de chaque colonne.
Voici les scores décrits dans le tableau (d’après D. Dascalu, 2021).
score d’importance des tours de parole : calculé par l’algorithme Page Rank de Brin & Page (1998), ce score étant d’autant plus élevé que ce tour de parole est sémantiquement relié à d’autres tours de parole (indépendamment des participants), et donc à la discussion entière.
in- et out-degree : un score in-degree (entrant) élevé d’un tour de parole signale que ce tour entretient des relations sémantiques importantes avec plusieurs tours de parole qui le suivent ; un score out-degree (sortant) élevé, à l’inverse entretient des relations importantes avec plusieurs tours qui le précèdent. Un tour de parole avec des scores entrants élevés montrent que les idées de ce tour vont avoir un effet/écho ultérieurement ; un score sortant élevé d’un tour montre qu’il reprend des idées antérieures. Des scores entrants et sortants sont également calculés par participant, en direction de chacun des autres (voir Figure 1).
score de construction sociale de connaissances : ce score est d’autant plus élevé que le tour de parole est sémantiquement relié à des tours de parole d’autres participants (calculé comme la somme de tous les liens entrants et sortants reliant 2 tours de parole de 2 participants différents).
Voici maintenant le descriptif de chaque graphique produit.
Graphique de l’évolution des contributions tout au long de la discussion#
Dans l’onglet “Contributions” est affichée la Figure 1, qui résume visuellement une grande partie des informations du tableau, décrites plus haut (importance, construction sociale de connaissances, liens entrants/sortants). Là aussi, survoler une partie du graphique indique des informations supplémentaires d’un tour de parole donné, et les mêmes outils permettent de réaliser une sauvegarde de la figure et des zooms ou dézooms. De plus, cliquer sur un nom de variable dans la légende affiche/cache la représentation graphique de cette variable.
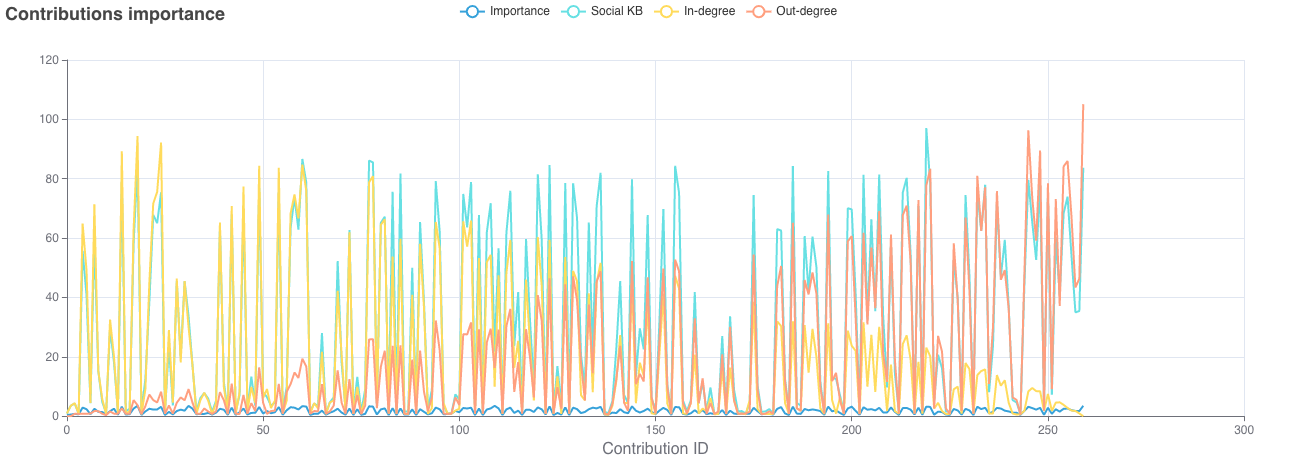
Figure 1 — Graphique de l’évolution des contributions tout au long de la discussion
Graphe de communication dirigé par la force#
Le deuxième onglet “Participants” affiche les autres visualisations. La première figure (voir Figure 2 ci-dessous) de cet onglet représente un graphe dirigé par la force (force-directed) qui décrit l’intensité de communication entre les participants. La taille de chaque nœud est proportionnelle au nombre de sommets entrants et sortants, passer la souris sur chaque sommet du graphe indique les scores entrants et sortants par binôme de participant.
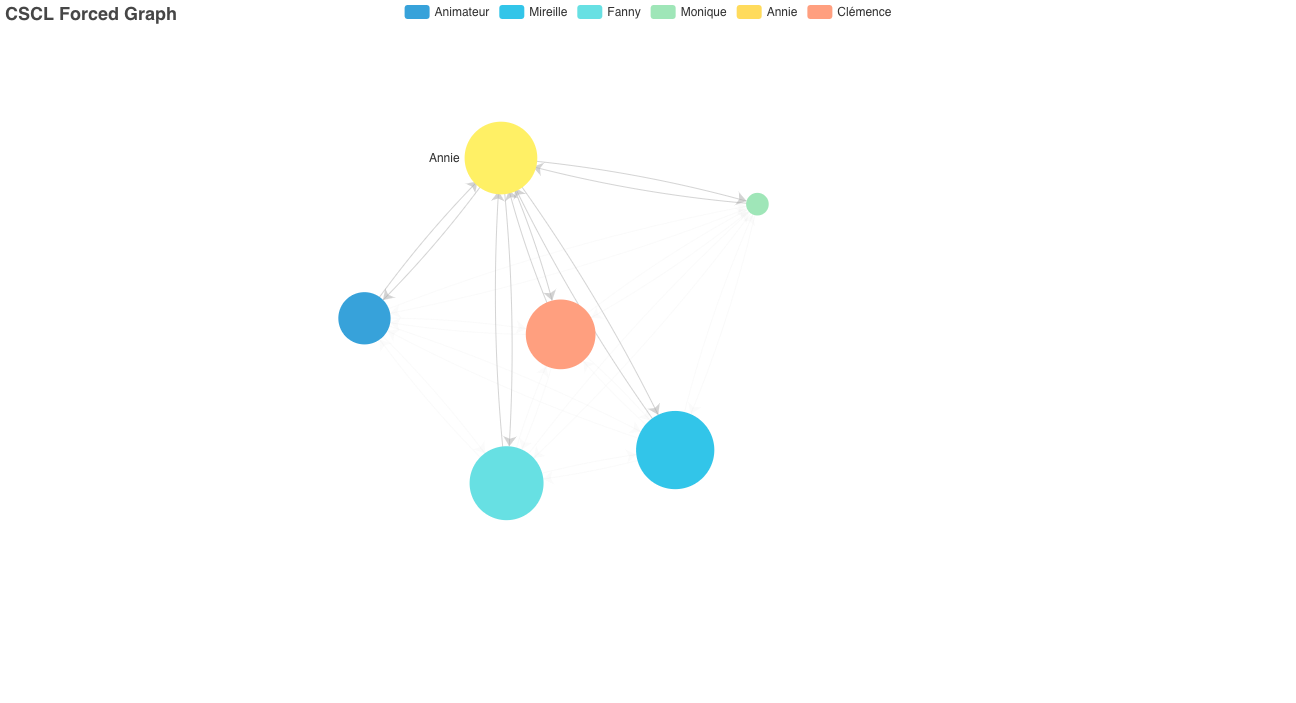
Figure 2 — Graphe des relations entre participants
Évolution des contributions des participants#
La Figure 3 représente la contribution de chaque participant·e de manière cumulée tout au long de la discussion (les tours de parole sont en abscisses et l’intensité de la contribution en ordonnées). Ici aussi, survoler la figure permet d’afficher les scores par participant). Des outils en haut à droite permettent respectivement de télécharger l’image, de zoomer et dézoomer.
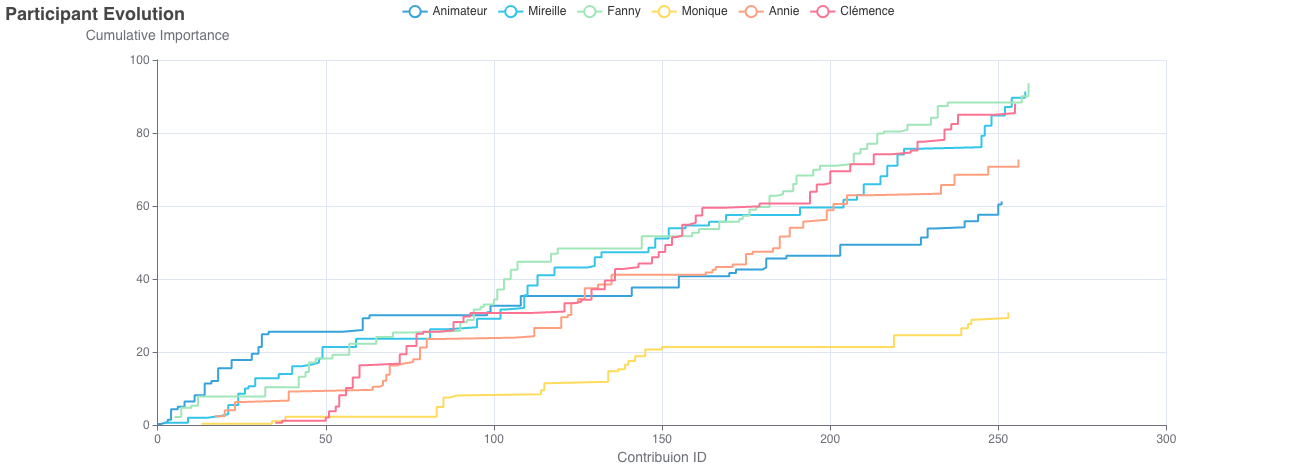
Figure 3 — Évolution des contributions des participants
Graphe circulaire de communication#
La Figure 4 est une manière différente (circulaire) de représenter les informations de la Figure 2.
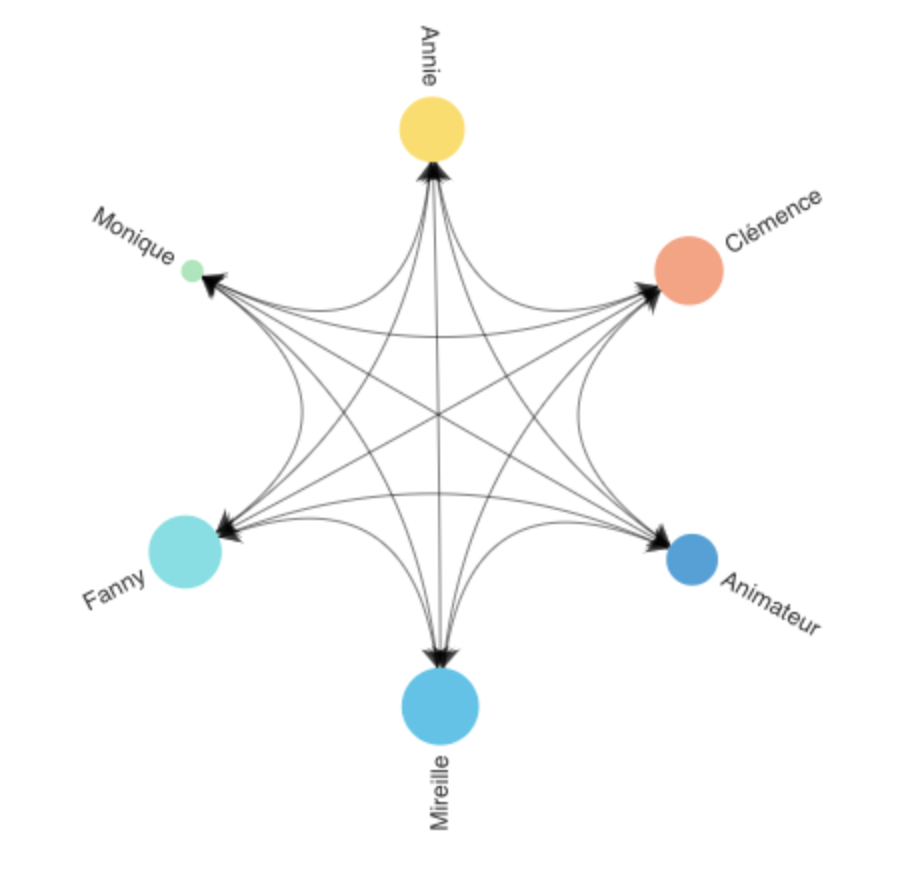
Figure 4 — Graphe circulaire relations entre participants
Références#
Brin, S., & Page, L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30, 1–7.
Broc, G., Carré, C., Valantin, S., Mollard, E., Blanc, V., & Shankland, R. (2017). Thérapie cognitive et comportementale et thérapie positive par le jeu : une étude pilote comparative. Journal de Thérapie Comportementale et Cognitive, 27 (2), 60–69. doi: 10.1016/j.jtcc.2016.12.002
Dascalu, D. (2021). Assessing Writing and Student Performance using Natural Language Processing and a Dialogical Framing. (PhD Thesis in computer sciences), University Politehnica of Bucharest, Bucharest.
Dessus, P., & Jolivet, S. (2016). CONPA : Un jeu de création et réflexion sur l’usage du numérique