Des protocoles à cas unique pour mesurer l’effet d’interventions éducatives#
Information
Auteurs : Philippe Dessus, Inspé & LaRAC, Univ. Grenoble Alpes.
Date de création : Nov. 2023.
Résumé : Ce document décrit quelques protocoles (quasi-)expérimentaux pouvant être mis en place en contexte scolaire pour mesurer l’effet d’interventions éducatives.
Note : Ce document cite intensivement la conférence de Thierry Atzeni, Univ. Savoie-Mont-Blanc (2023), Approcher la causalité au-delà de l’essai contrôlé randomisé : l’exemple des protocoles à cas unique. In 4e Workshop de Pegase (UGA) en 2023.
Introduction#
Il est très délicat et coûteux de mener, dans des contextes scolaires, des expérimentations très contrôlées (avec un ou des groupes-contrôle) et randomisées. Elles nécessitent un grand nombre d’élèves dans des classes différentes, et une aléatorisation des interventions ou des groupes-classes. De plus, ces études posent des problèmes éthiques, puisqu’on va sciemment proposer à des élèves des situations qui ne sont pas optimales pour l’apprentissage (celles des groupes-contrôle).
La recherche sur des cas uniques est moins coûteuse puisqu’elle se centre sur le comportement ou les performances d’un seul élève (ou, par extension, d’un groupe d’élèves ou une classe) et son observation au cours du temps. Le protocole consiste en les mesures multiples d’un indicateur avant l’introduction d’une intervention pédagogique, puis en d’autres mesures une fois que l’intervention est mise en place, puis, une fois qu’elle s’est finie [Garon & Theoret, 2005]. Ces pratiques de recherche sont courantes dans certaines disciplines, comme la psychologie clinique.
Ainsi, cela autorise la mise au jour de relations causales possibles entre un comportement (Cn) donné (la performance d’un ou plusieurs élève·s), et les variables pouvant influer sur ce dernier (l’absence d’intervention, A, ou sa présence, B), antérieures ou postérieures à ce comportement. On pourra donc dire :
Si A, alors C1 ; Si B, alors C2
Tester l’effet d’une intervention éducative#
La machine à remonter le temps ?#
On s’intéresse à tester l’effet d’une intervention (enseignement d’une notion d’une matière, selon une méthode pédagogique donnée) sur les élèves d’une classe donnée. Imaginons une classe dans laquelle un·e enseignant·e aura mis en œuvre une méthode pour améliorer la compréhension en lecture de ses élèves. Comment être sûrs que c’est bien l’intervention elle-même — et pas d’autres variables ou événements — qui aura causé l’amélioration des élèves ? Nous empruntons ce qui suit à [Ferry-Danini, 2023]. Ce n’est pas parce que l’amélioration en compréhension se produira après l’intervention que celle-ci aura causé celle-là. L’enseignant·e peut très bien avoir une capacité à enseigner la compréhension, indépendamment de l’intervention ; la compréhension des élèves peut aussi avoir évolué positivement à ce moment-là ; ils ont pu être massivement aidés par leur famille ; ils ont pu progresser parce qu’ils ont fait l’objet d’une attention particulière de l’enseignant·e. Donc, même si nous avons intuitivement tendance à interpréter deux événements successifs comme liés par une causalité, nous pouvons nous tromper.
Alors, comment être sûrs ? [Ferry-Danini, 2023] montre qu’une manière sûre, bien qu’irréalisable, serait de comparer le niveau de compréhension d’un groupe-classe après intervention, au niveau de ce même groupe-classe sans intervention, toutes choses égales par ailleurs. C’est la seule manière d’évaluer les effets de cette intervention, et elle est impossible à réaliser. On peut imaginer, en revanche, qu’on réalise l’intervention avec un groupe d’élèves et qu’on utilise une machine à remonter le temps pour revenir juste avant l’intervention, et qu’aucune intervention ne leur soit présentée. Comparer le niveau de ces deux groupes au même moment permettrait assurément d’évaluer l’effet de l’intervention.
Comme ce type de machine n’existe pas, on va utiliser à la place une comparaison entre un groupe d’élèves “expérimental“, confronté à l’intervention et un groupe d’élèves “contrôle“ qui n’y sera pas confronté. Toutefois, si le groupe expérimental réussit mieux que le groupe-contrôle, ce peut être pour d’autres raisons que celles de l’efficacité de l’intervention : il peut être de meilleur niveau initial, avoir été plus aidé à la maison, etc. Il est donc nécessaire de faire en sorte que les deux groupes soient les plus équivalents possible. Une solution, toujours en suivant [Ferry-Danini, 2023], est de recourir à l’aléatorisation de la constitution des groupes d’élèves, ou des classes. Ainsi, on évitera plusieurs biais, dont celui d’avoir l’enseignant·e le ou la plus motivé·e pour enseigner la compréhension dans le groupe expérimental.
Le protocole AB#
Mais il est assez délicat de créer, en situation scolaire, des groupes d’élèves aléatorisés, ou de trouver des classes assez similaires pour pouvoir les comparer. La solution alternative est d’observer la sensibilité d’une même classe aux changements, si possible répétés au cours du temps, entre une condition A (sans intervention) et une condition B (avec intervention).
On va ainsi comparer le niveau d’une ou plusieurs variables dépendantes (VD) dans le temps, nommées aussi indicateurs, selon qu’elles se situent dans une phase A, qu’on va nommer “niveau de base” (i.e., ou baseline, enseignement-apprentissage “standard”) ou bien une phase B, “intervention”, dans laquelle va se dérouler l’intervention à évaluer.
Les performances des participants vont donc être mesurées de manière répétéee dans chacune de ces phases (entre 3 et 5 fois) : on appelle ces protocoles “arrêt-reprise”. Si l’intervention a un effet, on peut prédire, au cours du changement des phases, une “réaction” du niveau des VD, qui vont être de niveau habituel pour les phases “niveau de base” et de niveau différent (meilleure performance, nombre d’erreurs moins élevé) pour les phases “intervention”.
Le choix des indicateurs#
Des indicateurs précis, complets et non équivoques#
L’indicateur doit être opérationnel, c’est-à-dire défini a priori de la manière la plus précise, complète (tous les comportements possibles listés) et non équivoque possible (on ne peut confondre le comportement avec un autre). Il est de très loin préférable qu’il soit observable directement plutôt qu’inférable par l’enseignant concerné. Enfin, cela va sans dire, il est nécessaire que les indicateurs recueillis soient en lien avec une théorie.
Par exemple, les indicateurs suivants répondent à ces critères, et concernent des fréquences (nombre d’occurrences par unité de temps) et des durées :
nombre de prises de parole volontaires (ou leur durée) ;
nombre de mots écrits ou lus par un élève ;
nombre de jours d’absence, etc.
[Plavnick & Ferreri, 2013] p. 551 donnent des exemples d’indicateurs opérationnels pour les trois activités suivantes :
Relire et corriger des erreurs d’une production écrite : L’élève lit la phrase qu’il a écrite à haute voix ou silencieusement et prend des mesures pour la corriger, si nécessaire. Les exemples de correction sont (indicateurs) : la mise en majuscules de la première lettre d’une phrase, la correction d’un mot mal orthographié, l’ajout de ponctuation ou l’inversion de l’ordre des mots. Si l’élève ne parvient pas à repérer ou à corriger une erreur, l’enseignant note cette étape comme incorrecte.
Additionner et soustraire : L’addition et la soustraction sont mesurées en enregistrant le nombre de chiffres corrects par minute. Les chiffres corrects sont définis comme le nombre approprié écrit dans la colonne appropriée.
Changer une activité : Lorsque un élève a l’air de s’ennuyer ou d’être désintéressé, demandez-lui s’il veut jouer à autre chose. Sortez un nouveau jeu ou une nouvelle activité que l’autre personne a déclaré vouloir pratiquer. Jouez au nouveau jeu. Compter le nombre de fois que ce changement a lieu.
La temporalité des mesures#
[Lanovaz, 2013] explique aussi quand, et à quelle fréquence, recueillir des traces de comportement. Tout d’abord, il n’est pas nécessaire, et très coûteux, de l’observer toute la journée ; se fixer des plages d’observation limitées, mais justifiée par les événements qui s’y déroulent (e.g., observer les prises de parole pendant des temps de regroupement).
Lanovaz indique aussi qu’il faut choisir des périodes pendant lesquelles le comportement étudié a des chances de se produire un nombre suffisant de fois (de l’ordre de 10 à 20, au minimum). Et il est utile d’adapter la plage d’observation à la fréquence du comportement (un comportement très fréquent pourra mieux être observé sur des périodes plus courtes). Ainsi, la mesure pourra être sensible à un changement de comportement dû à l’intervention. Pour cela, réaliser une observation préliminaire, avant de décider, sera utile.
Le contexte de l’intervention doit enfin être déterminé précisément et ne pas varier au cours de l’étude, pour éviter que des variables confondantes ne biaisent les résultats.
Indicateurs reliés#
Si l’on a à choisir plusieurs indicateurs, il est important de vérifier qu’ils ne sont pas covariants (i.e., qui sont reliés). [Garon & Theoret, 2005] recommandent de ne pas observer à la fois l’attention à la tâche et le dérangement des pairs, puisqu’il est probable que lorsque l’attention globale augmente, le dérangement devrait baisser. Il est donc conseillé de se poser la question du lien entre les indicateurs choisis.
Description des protocoles à cas unique#
Ce qui suit est repris de la conférence de T. Atzeni (2023).
Protocoles AB(AB…)#
Dans le protocole le plus simple : AB, on s’intéresse à mesurer un niveau de base (A) d’un élève ou groupes d’élèves, selon un ou plusieurs indicateurs choisis, puis leur “réaction” à une intervention (B). Ce protocole s’apparente à un protocole de type “pré-post”, mais sans groupe-contrôle qui ne réaliserait pas l’intervention. Dans leur forme la plus simple, on les nomme plans AB avec suivi (c’est-à-dire, une évaluation des effets de l’intervention).
Pour cette raison, il est délicat d’attribuer la variation de l’indicateur à la seule mise en place de l’intervention. Beaucoup de facteurs comme la maturation des élèves, des événements scolaires extérieurs à l’intervention, par exemple, pourraient également causer la variation de l’indicateur. Une preuve définitive que l’intervention est réellement la cause de la variation de l’indicateur doit être obtenue en revenant au niveau de base après l’intervention, puis en observant une nouvelle réaction à l’intervention (protocole ABAB).
Il est donc essentiel de compléter ce protocole AB par l’arrêt aléatoire de cette intervention pour revenir à une phase A, et ainsi de suite. Le terme aléatoire est ici essentiel : on a à décider, à l’avance, combien de temps durera la phase B et ce temps est décidé au hasard. Ce sont des protocoles avec retrait”.
On considère (voir conférence de T. Atzeni, 2023) qu’on peut mettre en évidence une relation causale entre le changement de comportement du ou des élève·s et le changement de phase à partir de ces 4 phases ABAB. Atzeni indique également que, pour améliorer la qualité de la relation causale, on peut :
augmenter le nombre de paires de phases AB (i.e., ABABABAB) ;
augmenter le nombre de phases et rendre leur tirage aléatoire, par blocs (i.e., ABBABBABB) ;
augmenter le nombre de phases et rendre leur tirage aléatoire (i.e., ABAABABABB) ;
introduire plusieurs types d’interventions au cours du temps, par blocs ou aléatoirement (i.e., ABABACAC) ;
La Figure 1 (tirée de [Plavnick & Ferreri, 2013],) illustre, avec un exemple fictif, la manière dont un protocole ABAB peut se réaliser et ses résultats, à propos de l’indicateur “Pourcentage de devoirs faits”. Il est visible qu’il y a une réaction à l’intervention, et que le pourcentage de devoirs faits baisse à nouveau une fois que l’intervention cesse.
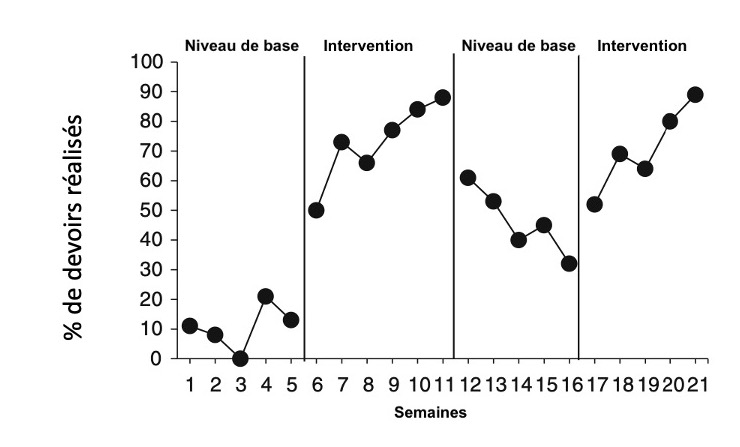
Figure 1 - Exemple fictif d’un protocole ABAB (repris de [Plavnick & Ferreri, 2013], p. 554).
Il faut noter que, dans ces protocoles, l’élève, ou le groupe d’élèves observé joue à la fois le rôle de groupe-contrôle (lors des phases A) et de groupe-témoin ou expérimental (lors des phases B). Notons aussi que, comme pour toutes les études avec groupe-contrôle, arrêter une intervention pour revenir à un niveau de base pose des problèmes éthiques : on aurait pu permettre un meilleur apprentissage en ne le stoppant pas.
Dernier commentaire important tiré de [Gana et al., 2019] : à partir du 2e arrêt de l’intervention (donc, le 3e A de la séquence ABABA), les participants ont réalisé un apprentissage qui ne les ramènera pas au niveau du 1er A, mais sans doute au niveau du 2e, la représentation des scores suivant plutôt un escalier.
Protocole avec alternance de traitements#
Ce protocole alterne plusieurs interventions (2 ou 3), au sein d’une même session (plutôt rare) ou entre les sessions, sous un format AB (donc AB1B2B2B1B1B2) ; il nécessite de réaliser de nombreux points de mesure pendant les interventions.
Protocole à critère changeant#
Ce protocole a également 2 phases (AB), et on choisit un critère pouvant renforcer un comportement, et ce critère va être modifié au cours du temps, afin de vérifier si le comportement change bien en fonction de la variation du critère. On modifie le critère dès que le comportement se stabilise à un niveau, et cela jusqu’à arriver à un niveau de comportement attendu.
Protocole à niveau de base multiples#
Ce type de protocoles sont des séries de protocoles AB, dans laquelle la phase B arrive de manière aléatoire, à travers les participants, les contextes, ou les comportements. Il n’y a pas de retrait de l’intervention, ce qui est plus satisfaisant d’un point de vue éthique. Le traitement des données est plus complexe, mais on peut dans ces cas observer les différences de comportement intra-individuel ou inter-individuel :
à travers les participants : une intervention est appliquée à plusieurs participants, tous exposés au même niveau de base ;
à travers les comportements : une intervention est appliquée à des moments différents, ciblant chez un même individu des comportements indépendants ;
à travers les contextes : une intervention est appliquée à des moments différents, à un seul individu placé dans des contextes différents et indépendants, en se centrant sur un seul comportement.
Une application pour analyser les résultats#
L’application Shiny SCDA de [Bulte & Onghena, 2013], voir ce site alternatif, dont l’aide se trouve dans ce site. Des jeux de données de test se trouvent ici et il est plutôt aisé de comprendre le fonctionnement basique du logiciel. Il permet de générer les graphiques d’évolution des scores en fonction des phases AB. L’article de Gana et al. (section 5) contient un mode d’emploi d’une version antérieure du logiciel.
Conclusion#
Pour résumer, voici les éléments à déterminer lorsqu’on réalise une recherche à cas uniques :
Choisir le design de l’étude (AB, ABAB…).
Déterminer les indicateurs à observer, s’assurer qu’ils soient précis, non ambigus, complets, et reliés à la théorie.
S’assurer que les indicateurs ne soient pas covariants.
Déterminer les plages d’observation.
S’assurer de la fréquence d’occurrence des indicateurs au sein des plages.
Dans le cas d’une étude AB(AB…), déterminer aléatoirement le moment où l’intervention va être interrompue, ainsi que le nombre de fois où cette dernière va survenir.
Webographie#
Vidéos du 4e Workshop du Pôle Pegase (UGA) en 2023.
Atzeni, T. (2023). Approcher la causalité au-delà de l’essai contrôlé randomisé : l’exemple des protocoles à cas unique.. 4e Workshop de Pégase. Grenoble : Univ. Grenoble Alpes.
Références#
- Bulte & Onghena, 2013
Bulté, I., & Onghena, P. (2013). The single-case data analysis package: analysing single-case experiments with r software. Journal of Modern Applied Statistical Methods, 12(2), 450-478. doi:10.22237/jmasm/1383280020
- Ferry-Danini, 2023(1,2,3)
Ferry-Danini, J. (2023). Pilules roses. Paris: Stock.
- Gana et al., 2019
Gana, K., Gallé-Tessonneau, M., & Broc, G. (2019). Le protocole individuel en psychologie : tutoriel à l’usage des psychologues praticiens. Pratiques Psychologiques, 25(2), 153-167. doi:10.1016/j.prps.2018.11.002
- Garon & Theoret, 2005(1,2)
Garon, R., & Théorêt, M. (2005). Re-connaître les plans à cas unique en sciences de l’éducation. Mesure et évaluation en éducation, 28(1). doi:10.7202/1087725ar
- Lanovaz, 2013
Lanovaz, M. J. (2013). L’utilisation de devis expérimentaux à cas unique en psychoéducation. Revue de Psychoéducation, 42(1), 161–183.
- Plavnick & Ferreri, 2013(1,2,3)
Plavnick, J. B., & Ferreri, S. J. (2013). Single-case experimental designs in educational research: a methodology for causal analyses in teaching and learning. Educational Psychology Review, 25(4), 549-569. doi:10.1007/s10648-013-9230-6